Starling Lab hosted a three-part Seminar Series at Stanford University on new ways to guarantee the authenticity, availability, and persistence of images, as well as metadata and attestations about the images.
I was invited to give the initial presentation to kick off the second part of the series, Authenticated Databases, which included a panel discussion with speakers from Ceramic, Fission, and Fireproof Storage.

Download all slides as a pdf.
The full recording hasn’t yet been released, but here’s a “trailer” of the talk.
Transcript

Hi everyone, thank you so much for coming. My name is Kate Sills, and I’m a software engineer and consultant, and today I’d like to introduce a project I worked on with Starling Lab, called Authenticated Attributes.
Authenticated Attributes is a tool that allows open source investigators to verify images by sharing authenticated metadata and attestations about the image. In other words, it’s a tool for sharing info about images in a way that can’t be faked or tampered with.
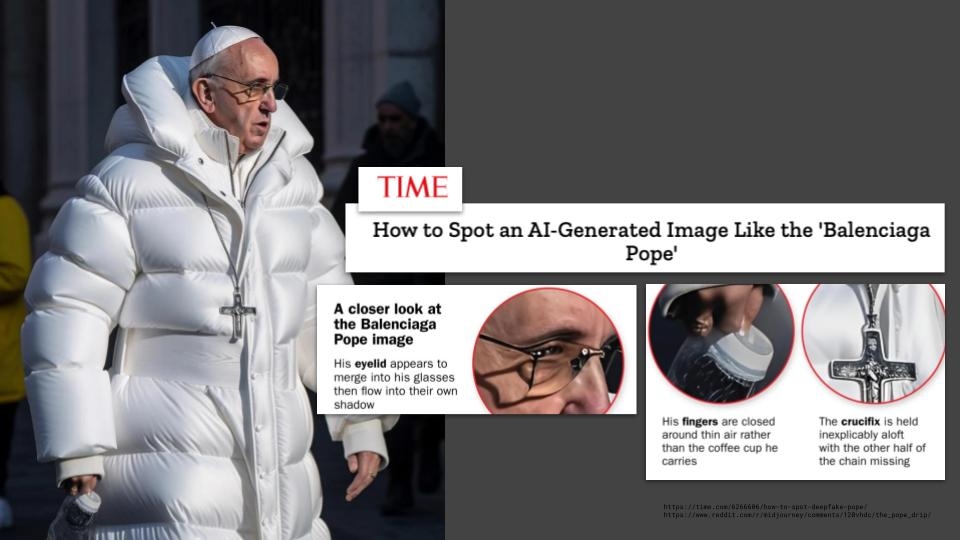
Why do we need this? Well, with the rise of generative AI, now we can’t trust what we see. This image looks like the Pope wearing a white puffer jacket, but it’s fake. And although right now there are certain characteristics that reveal this as an AI generated image, those characteristics are going to go away, making AI generated images indistinguishable from real images, even with software detection.
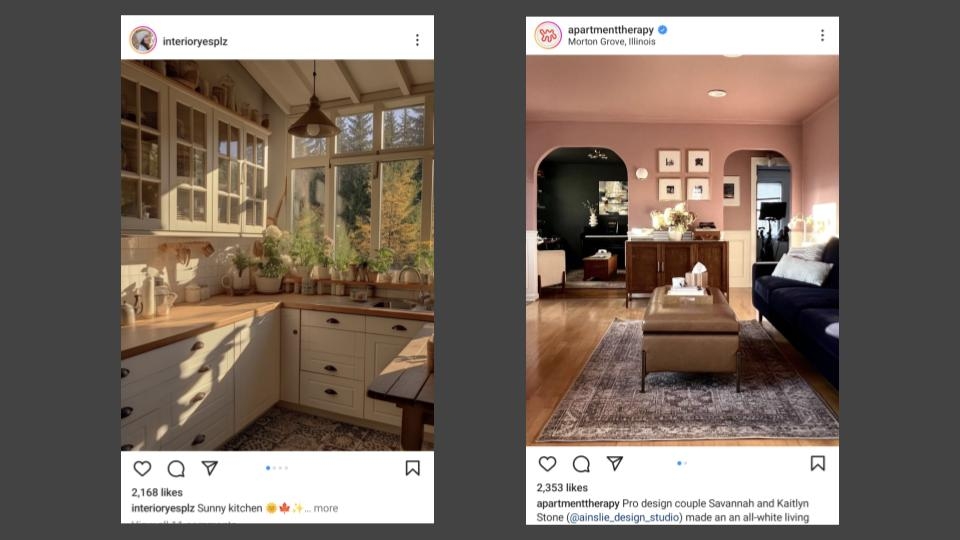
What can we do? This is a screenshot of a post that was in my instagram feed recently. It’s a fake photo. So the question is, if, in the future, this picture looks exactly like a real image, to both humans and software, how can we tell whether it’s a real image or not?
Well, here’s a real image on the right, that we can use to compare. And if we look at the two screenshots, there are some real differences. For the image on the right, we know information, like the location, the photographer, the publisher, the subjects.

In the future, there will be two classes of images. Those without credible metadata, attestations and supporting documents, and those with. And AI-generated photos and other fake photos are going to fall into the without category.

So I can see you thinking already, can’t we just use AI to generate fake data as well?

And yes, we can generate fake data. But there are some kinds of data, some things, that can’t be faked, and that’s what our society will depend on.

I’m going to focus on two things. First, we can make to impossible to credibly backdate an image. And I’ll go more into depth on this in a second.

And second, we can make it nearly impossible to fake sources and tamper with claims.

So to make it impossible to credibly backdate an image, we can use what is called a timestamping service. A timestamping service allows you to submit a photo or file and get a proof back that the file existed before a certain point in time.

You can think of a timestamping service like a service that takes the image you provide, and then prints the image in the New York Times. Obviously, that’s not exactly how it works, because that would be inefficient, and I’ll talk about the inefficiency in a second. But if we did this, what would it give us?
Well, we would know for sure that the image was created before the date the newspaper was printed. The image could not have been created after the newspaper was printed—that’s not how reality works. So we know, without needing to trust anyone, that the image was created before the date of the newspaper.

So, to fix the efficiency problem, we can use cryptographic hashes. Cryptographic hashes are a unique identifier for the file derived from the contents. And if anything changes in the image, a bit, a pixel, the hash will change drastically. The hash, because it’s a unique identifier, can also be used as a summary or digest for the image.
So we have this tool that allows us to create identifiers that uniquely summarize the image. And we can use this to fix our efficiency problem.

So instead of printing the image in the New York Times, we can print the hash that summarizes the image.
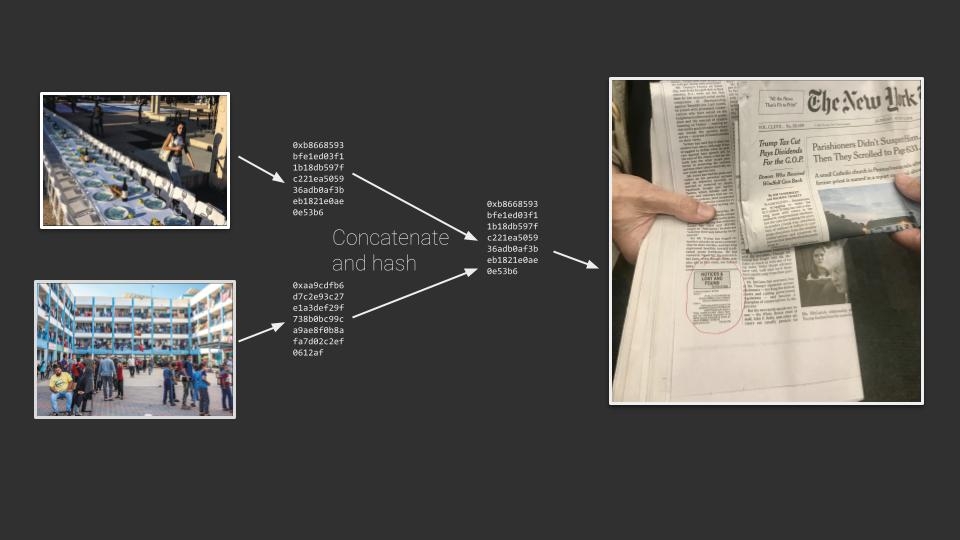
And we can do this recursively. We can concatenate and hash hashes, so that we can summarize multiple images into a single hash that gets recorded.
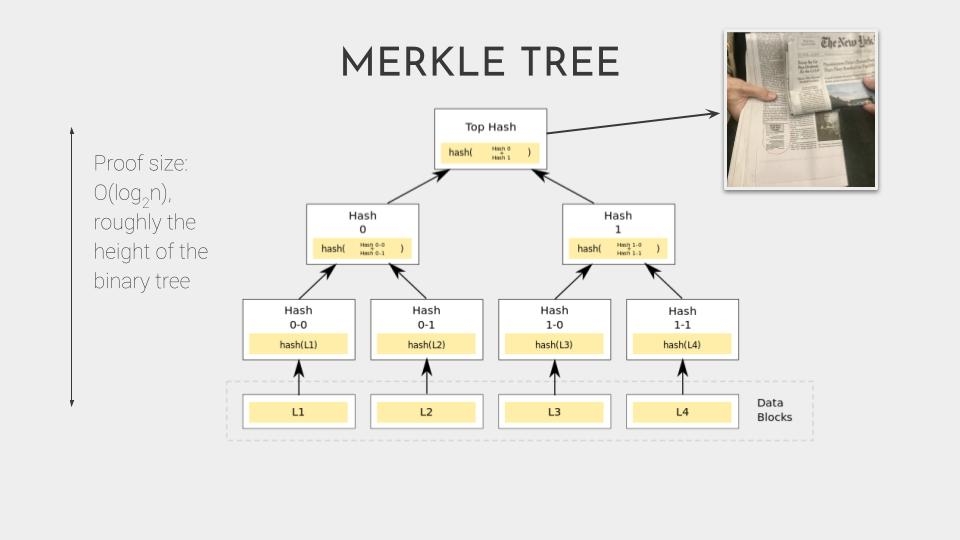
And if we flip this on its side, we get what’s called a merkle tree. The images or data are at the bottom, and each level above is a hash summarizing what is below. This means that the value at the top, at the root of the tree, is a summary of everything within it. And we can record that value to timestamp all of the data in the tree.

So recording the value, committing to the value is known as anchoring. And there is a company that started in the 90s called Surety which really did anchor in the New York Times. This is Stuart Haber, one of the inventors of secure timestamping, showing the actual entry in the New York Times classified section.

But anchoring doesn’t have to be in a newspaper. OpenTimestamps, which is what Starling Lab uses, anchors on Bitcoin, and Ceramic, which is part of the panel here today, anchors on Ethereum.
So that’s timestamping and anchoring, which we’ll hear more about during our panel.

To achieve our second goal, of making it nearly impossible to fake sources and tamper with claims, we can use something called digital signatures.

Digital signatures allow us to sign data in a way that can’t be forged or repudiated. Digital signatures use public key cryptography—a signer has both a public and private key, and uses the private key to sign over a piece of data. Anyone with the public key can verify that the holder of the private key did indeed sign.

This allows us to share and ingest second hand data as if it came directly from the source. So if I just tell you Time Magazine said something, you probably shouldn’t trust me and should go directly to Time Magazine to see if they did say it. But if instead, Time Magazine digitally signs a statement, I can give you that signed statement, and you can verify the signature and know that 1) Time Magazine said it, and 2) I didn’t tamper with it in transit, all without trusting me at all.

Ok, so now that we’ve discussed some of the underlying technology, let’s go back to Authenticated Attributes project. Image verification, determining whether an image is true or false, is fuzzy, messy, and deeply human. None of the cryptographic tools can help us determine whether a claim is true. We can know who made the claim and whether it has been tampered with, but the truth depends on the quality of sources, and that can only be determined through investigation. So for instance, in this photo, open source investigators geolocated the photo by matching the houses in the village to those in a satellite image.
Verification and investigation creates a web of knowledge, it requires collecting more web pages and images and documents that support or disprove the claim.
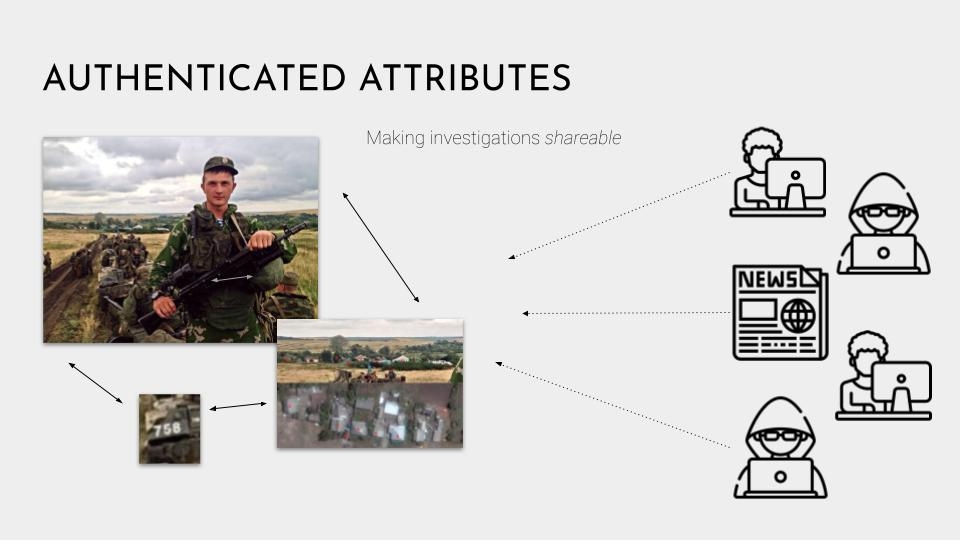
And Authenticated Attributes is a way to share these images, supporting documents, metadata, and attestations in a way that is authenticated. In other words, everything is individually digitally signed and timestamped.
So generally open source investigators and photographers use some kind of software such as Fotoware, and Document Cloud, to organize their data, for the Authenticated Attributes demo, we chose to use Uwazi which is used by human rights groups all over the world.

So the architecture is divided into three layers.
First, the front-end which is just a modified version of what is already used in the field.
And then the middle layer is the actual authenticated data. So for instance, a photographer might claim that the photo was taken in a particular location. That claim itself is digitally signed and timestamped and shareable with others. And can be put in IPFS itself, even without the image.
And then the ground layer is Hyperbee, which is a peer-to-peer database built on top of an append-only log that uses merkle trees. This allows us to easily summarize a snapshot of the database by recording its hash, to know instantly if the database has changed since we last saw it, to revert back to a prior version, replay the entire history of the database, and other cool features.
Importantly, any client can choose which Hyperbees to listen to, and which to ignore. So you get to choose your sources, and if the values conflict, an investigator can compare the different values. There is no need to overwrite or consolidate information prematurely.

So I believe I’m running out of time here, but lastly I wanted to show the authenticated data schema for those interested. Each individual claim is digitally signed and timestamped, and the images are referenced by their hash, technically a CID. We can associate two images together by linking their CIDs and we can even make comments about other attestations by referencing the CID of the attestation.
So in summary, we’re entering a time in our society when we can no longer trust what we see, where data can be entirely faked. However, there are certain things, like timestamping proofs and digital signatures, which can’t be faked. So as a society we need to start using these tools, and the authenticated attributes project is a way to do that. It allows open source investigators to make claims and share these claims and metadata about images in a way that can’t be faked or tampered with.